Гипертекстовая система нормативной документации на основе технологии World Wide Web
1. Введение
Непрекращающийся в течение последних лет взрывной интерес к сети Internet и, в особенности, к ее технологии WWW вызвал небывалое количество статей в компьютерных изданиях по этой тематике. Большая часть статей обычно посвящена разъяснению основных понятий технологии, преимуществам тех или иных коммерческих продуктов или хитростям оформления гипертекстовых страниц.
Зачастую, после чтения таких обзорных статей у нас, читателей, появляются смешанные чувства. С одной стороны, восторг от замечательно оформленных страниц серверов WWW, а с другой - законный вопрос: а как всю эту красоту можно приспособить для каких-нибудь "серьезных" потребностей? "Несерьезные" задачи наподобие публикации курсов иностранных валют или прогноза погоды уже решены на всех российских серверах WWW.
Этот законный вопрос про "серьезные" задачи возник и у нас после того, как на нашем сервере WWW появилось несколько картинок и телефонный справочник нашего предприятия.
2. "Серьезная" задача
На любом предприятии есть архивы. Это и переписка, и приказы, и инструкции, и положения. Чего только нет. Что делать с архивами обычно никто не знает. Выбрасывать бумаги в мусорную корзину - такой выход не все могут себе позволить. Как правило, документы складываются по тематике и по годам в огромные папки, найти в которых что-нибудь практически невозможно.
У нас тоже есть особый архив - архив нормативной документации, в котором хранятся стандарты (ГОСТы, ОСТы и пр.), извещения об изменениях в стандартах. В стандартах кроме собственно текста есть пояснительные рисунки, таблицы, и графики. Одни стандарты ссылаются на другие, а те - на третьи. У каждого стандарта есть срок ввода его в действие, а у некоторых - и срок окончания действия, после которого он заменяется другим стандартом. Каждая книга имеется в нескольких экземплярах, которые хранятся у читателей. Ходовых книг на всех не хватает. Когда в стандарте проводится изменение, работники архива собирают все экземпляры этого стандарта, вписывают в них изменения и снова раздают читателям.
Словом, в архиве хранится большое количество разнородной (текстовой, рисованной, чертежной, табличной) информации с множественными (сетевыми) связями. Информация не имеет четкой единообразной структуры. На бумажных карточках ведется несколько поисковых каталогов с алфавитными перечнями названий документов, обозначений документов, документов с истекающим сроком применения и др.
Требуется обеспечить компьютерное хранение нормативной документации с автоматизированным составлением всех поисковых каталогов, с доступом пользователей к архиву через локальную сеть. Одновременно желательно разрешить пользователям копировать или встраивать элементы архивных документов (текст, рисунки, чертежи) в свои программы и документы. Желательно также организовать для пользователей локальной сети компьютерную библиотеку основных машиностроительных (AutoCAD) и радиоэлектронных (PCAD) элементов для их заимствования.
Известные нам компьютерные системы поиска нормативной документации, разработанные в бывшем СССР, приспосабливались в основном под потребности отделов стандартизации. Они построены на "персональных" СУБД класса FoxPro или серверах класса Oracle и хранят только реквизиты документов (обозначение, название, сроки действия и пр.) и краткую аннотацию. Полных текстов стандартов, а тем более рисунков, таблиц и чертежей в таких системах нет, хотя именно такие данные нужны другой категории пользователей архива - конструкторам.
Мы пришли к выводу, что систему хранения и поиска документации нам следует разработать самостоятельно.
3. Варианты решения
Хотелось бы сделать нашу систему возможно быстрее, на знакомых средствах и без значительных финансовых вложений. (Писать об этом, пожалуй, излишне: вряд ли кто-нибудь хочет делать работу подольше и подороже для себя, - но хочется подчеркнуть приоритеты разработки.)
Напрашивается один из трех вариантов построения компьютерного хранилища.
Первый вариант - применение СУБД. Очевидные преимущества этого подхода - в легкости построения поисковых перечней документов с различными условиями выборки. Недостатков значительно больше. СУБД предназначены для работы с четко структурированной информацией, а нормативная документация таковой не является. В широко распространенных реляционных СУБД весьма затруднительно создать множественные сетевые связи между объектами, а в нашей предметной области перекрестные ссылки одних стандартов на другие - распространенная практика. Многие СУБД позволяют иметь в каждой записи таблицы лишь одно поле BLOB, в котором можно хранить рисунок или чертеж, а для документа одного рисунка мало. Объем работ по программированию тоже велик: требуются проектирование базы данных и полная разработка клиентских приложений для пользователя-читателя и пользователя-администратора архива. Объем еще более возрастает, если пользователи работают в разных операционных системах. Ну и самый главный, пожалуй, контраргумент в том, что СУБД предназначены для решения другого класса задач, в которых данные в базе изменяются почти всеми пользователями почти одновременно и относительно часто, как это происходит в банковских системах или в системах продажи билетов. Значительная часть механизмов СУБД направлены именно на сохранение целостности данных при их одновременной модификации. В нашей чисто архивной задаче, где все пользователи, за исключением одного, являются читателями, эти механизмы базы данных будут неизбежно снижать производительность системы.
Второй вариант - применение специализированной системы обработки документов наподобие Lotus Notes. Это решение с учетом покупки новой системы, ее установки и обучения показалось нам дороговатым и нескорым. Тем более, что богатые возможности Lotus Notes, как, например, разграничение доступа к отдельным полям документов или некоторым документам, не будут востребованы в общедоступном архиве.
Выбор пал на гипертекст в формате языка HTML, который мы к тому времени изучили, да и особой сложности в нем нет. Опираясь на HTML, можно построить компьютерное хранилище, легко обеспечив множество сетевых связей между документами, их частями, любой графической (двоичной) информацией. Строгая структуризация документов, как для хранения в базе данных, не требуется. Утомительную разметку документов описателями (тегами) языка HTML можно облегчить, применяя бесплатные утилиты, имеющиеся на серверах ftp в Internet, или с помощью фирменных средств от, скажем, Microsoft. Доступ пользователей локальной сети к архиву через сервер WWW и любой из навигаторов обеспечивается по определению. (Навигатор Netscape, кстати, распространяется фирмой с ее узла WWW тоже бесплатно.) Таким образом, мы получаем проектное решение, полностью основывающееся на открытых стандартах (язык HTML, протокол http), бесплатные клиентские приложения - навигаторы - с перспективой получать их все более свежие версии. Причем навигаторы Netscape работают практически на всех программно-аппаратных платформах; это означает, что пользователи архива будут иметь единообразный доступ к нему из любых операционных систем. От нас требовалось разработать только структуру архива и автоматизировать создание поисковых каталогов, о которых говорилось в разделе 2. Прекрасной помощницей послужила нам серия статей в журнале BYTE (например, [1]).
4. Решение на основе HTML, Perl и World Wide Web
Итак, основное информационное наполнение архива составляют нормативные документы, размеченные описателями языка HTML. Один из таких документов приводится на рис. 1, а его вид в навигаторе - на рис. 2.
Фрагмент документа в формате языка HTML

Рис. 1
Значение тегов (описателей), помещенных в этот документ, подробно описано в руководствах для начинающих, например в [2],[3]. Редко встречается лишь тег , который играет ключевую роль в наших программах создания поисковых каталогов. Этот описатель допускается в заголовках документов; навигаторы его игнорируют, а другие утилиты могут использовать. Тег <meta>, отмечает в документе пару "имя/значение" (name/content), с помощью которой задаются реквизиты документа:
<meta name=title content= Общие требования к текстовым документам> <meta name=designation content=ГОСТ 2.105-79*>
Первая строка задает пару "title/Общие требования к текстовым документам" - реквизит "наименование". Вторая - задает пару "designation/ГОСТ 2.105-79*" - реквизит "обозначение" .
Вид документа в навигаторе Netscape

Рис. 2
Реквизитов может быть сколько угодно, для каждого нужно внести в документ свой тег . Подробное описание этого тега имеется в [4].
Теперь можно просканиривать документы программой, составить любые алфавитные поисковые каталоги и оформить их в виде новых документов в формате HTML. Эти каталоги являются "искусственно" созданными (с помощью программы), в отличие от исходных документов, составленных с участием человека-администратора архива. Новые документы - поисковые каталоги - очень похожи на "виды" системы Lotus Notes и обеспечивают простой, интуитивно понятный и эффективный доступ к нормативной документации. Пример "искусственного" документа находится на рис. 3, а его вид в навигаторе - на рис. 4.
Текст поискового каталога в формате языка HTML

Рис. 3
Вид поискового каталога в навигаторе Netscape
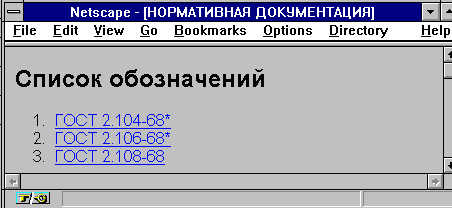
Рис. 4
Какой должна быть программа для построения поисковых каталогов? Конечно, лучше всего применить язык программирования Perl, специально предназначенный для обработки текстов. Мы приводим здесь листинги упрощенного и усеченного варианта программы, которая создает два поисковых каталога. Первый каталог - алфавитный перечень наименований документов, второй - их обозначений.
Перестройка поисковых каталогов делается по мере размещения в архиве новых документов. Вызов программы перестроения каталогов можно делать как из навигатора через интерфейс CGI, так и через telnet, что, впрочем, не совсем удобно. Конечно, право перестраивать каталоги предоставляется только администратору архива.
5. Заключение
Мы построили информационно-поисковую систему. Она прекрасно работает с гипертекстом, обеспечивает доступ по локальной сети, развивается вместе с развитием серверов и навигаторов WWW, она очень проста и надежна в эксплуатации. При хорошей связи эта система может работать в территориально удаленных сетях и в Internet. Эту систему нормативной документации легко перестроить под любые архивные, да и не только архивные, потребности. Она подойдет и для составления библиотечных (в общеупотребительном смысле) каталогов, и для редакционного архива в газете или журнале, и для архива чертежей (PCAD, ACAD), и для медицинских карточек с рентгеновскими снимками и кардиограммами, - везде, где имеется разнородная информация с множеством взаимных ссылок или где информацию нужно искать то по фамилии автора статьи, то по номеру журнала, то по названию книги. Наконец, такая информационно-поисковая система хороша тем, что она проверена в работе.
Список литературы
1. Udell J., Perl Magic, BYTE, 1995, 12, стр. 115-120.
2. Макартур Д.С., Всемирная сеть и улучшенный язык гипертекста, журнал д-ра Добба, 1995, 2, стр. 6-13.
3. Федоров А. Введение в язык HTML. Компьютер-пресс, 1996, 6, стр. 110-115.
4. Berners-Lee T., Connolly D. Hypertext Markup Language - 2.0, Request for Comments: 1866, Network Working Group, 1995.
Листинги
Листинги упрощенного варианта программы, которая создает два поисковых каталога. Первый каталог - алфавитный перечень наименований документов, второй - их обозначений.
#---------------------------------------------------------------------------
# Листинг 1
#---------------------------------------------------------------------------
# Просматривает файлы из списка, заданного в $ARGV.
# Отыскивает в них строки с реквизитами документов и
# помещает пару "реквизит/имя файла" в соответствующий
# массив. Затем сортирует массивы по реквизитам и
# строит новый документ - поисковый каталог.
#!/usr/gnu/bin/perl
$i=0;
$filename1="designation";
$filename2="title";
$title1="Список обозначений";
$title2="Список наименований";
while($ARGV[$i] NE ""){
$designation=&FindValue($ARGV[$i],"name=designation content=");
$title=&FindValue($ARGV[$i],"name=title content=");
push(@DESIGNATION,$designation.':'.$ARGV[$i]);
push(@TITLE,$title.':'.$ARGV[$i]);
$i++;
}
# Сортировка массивов
@DESIGNATION=sort @DESIGNATION;
@TITLE=sort @TITLE;
# Построение новых документов в формате HTML
&BuildHTMLFile($filename1,$title1,@DESIGNATION);
&BuildHTMLFile($filename2,$title2,@TITLE);
В массиве $ARGV находятся имена файлов, в которых надо найти
реквизиты документов. Строка, которую необходимо найти в
документе, выглядит примерно так "name=designation content=".
Функция push строит массивы @DESIGNATION и @TITLE, добавляя
новые записи по принципу стека. Оператор ":" выполняет
конкатенацию строк.
#-----------------------------------------------------------------------------------------
# Листинг 2
#-----------------------------------------------------------------------------------------
# Подпрограмма извлекает значение заданной пары
# "имя/значение"(name/content) из документа.
sub FindValue{
local($fn,$str)=@_;
open(fd,$fn);
$MetaContent="";
do {
$_=
документа, т.е. до тега .
#--------------------------------------------------------------------------------------------
# Листинг 3
#--------------------------------------------------------------------------------------------
# Подпрограмма извлекает значение заданной пары
# "имя/значение"(name/content) из строки документа.
sub GetMeta{
local($line,$meta)=@_;
if(index($line,$meta) ne -1){
@ret=split(/$meta/);
($ret=@ret[1])=~s/>//;
chop $ret;
}
else {
$ret="";
}
return $ret;
}
Функция split(/meta/) расщепляет строки в массив строк @ret.
#------------------------------------------------------------------------------------------
# Листинг 4
#------------------------------------------------------------------------------------------
# Подпрограмма просматривает каждый
# элемент массива, расщепляет его на поля
# и записывает их в формате HTML в поисковый каталог.
sub BuildHTMLFile{
local($which,$headline,@view)=@_;
open(TOC,">$which.htm");
print TOC"\n";
print TOC"<h2>$headline</h2>\n";
print TOC"<bоdy><ol>\n";
foreach $item(@view) {
($first,$second)=split(/:/,$item,2);
print TOC"<li><a href=\"$second\">$first</a>\n";
} print TOC"</ol></bоdy></html>\n";
close (TOC);
} Каждая строка массива @view расщепляется относительно ":" на
поля first и second , которые записываются в формате HTML во
вновь создаваемый файл.